TrailBlazer: Trajectory Control for Diffusion-Based Video Generation
authors:
Wan-Duo Kurt Ma,J. P. Lewis,W. Bastiaan Kleijn
原文链接
Introduction
T2V 模型虽然已经能够产生视觉质量和内容一致性都很好的视频,但是缺乏一定的可控性,包括空间布局和物体的轨迹移动。一些方法通过提供一些 low-level 的控制信息,比如 canny edge maps 或者 skeletons 使用 ControlNet 来进行指导。这些方法虽然能够实现很好的指导,但是需要相当多的精力来产生这些控制信息。
为了解决这个问题,论文提出了使用 high-level 的控制信息来控制物体的轨迹。用户可以提供一些简单的 boxs 以及对应的 prompt 来描述物体在某些关键帧上的运动情况(关键帧之间使用插值获得)
在之前的工作[1]中发现,物体的位置在去噪过程中的前几步就已经建立起来了。
Peekaboo 在调整 attention 时对于背景区域使用了负无穷的修改,这使得背景结果出现了细节丢失的情况
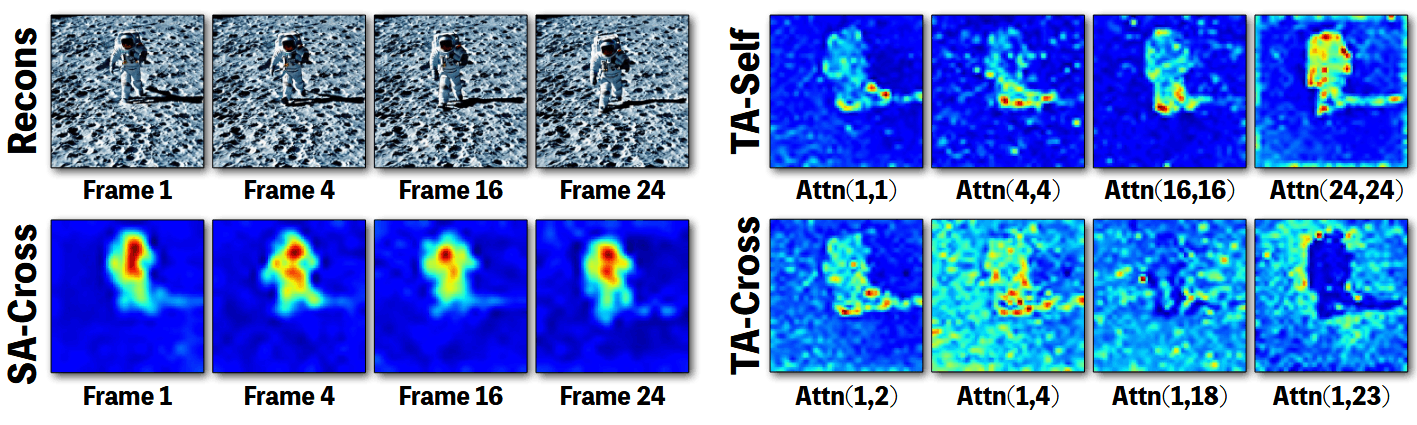
对于三种 attention 的一些观察:
- 在时间跨帧注意力上,随着帧距离的增加,注意力在物体区域的关注逐渐减弱,而在背景区域则有更多的关注,这与第一幅图的结果一致,第一帧和最后一帧在背景上几乎保持静态,而宇航员的位置有了明显的变化
Method
Define
TrailBlazer 基于开源的预训练模型 ZeroScope,能够生成高质量的视频且没有明显的抖动现象产生。
对于每个需要控制的区域,使用一组参数集合进行表示
表示控制框,,定义了一组框内像素点的集合,具体来说是通过四个标量表示框的相对位置 ,对于 Unet 不同层的分辨率是不相同的。
表示主体在 prompt 中的位置 ,比如在“a cat sitting on the car”中,‘cat’对应 2
表示尾随注意力映射索引,就是没有 prompt 对应的一些 tokens,
Pipeline

Spatial Cross Attention Guidance
其中 , 即 是减弱框外的, 是增强框内的, 表示一个高斯窗口,不同帧之间的框的位置和大小使用插值的方法得到。
Temporal Cross-Frame Attention Guidance
由于时间跨帧注意力在前半段是框内增强,后半段是减弱的,因此采用随帧变化的权重进行处理
其中
Scene compositing
如果希望处理多个物体或者多种运动,直接对参数修改是比较繁琐的,需要找到一种比较折中的参数。因此,可以使用对 latent 加权的方式组合 prompt
其中
这个的含义是对于开始的时间步骤, 充分考虑 , 到后面的 之后的时间步骤,则忽略 , 继续正常的去噪步骤
References
[1] Magicmix: Semantic mixing with diffusion models.
正在加载今日诗词....
📌 Powered by Obsidian Digital Garden and Vercel
载入天数...载入时分秒...
总访问量次 🎉